Over the past few weeks, I’ve been on an intensive learning journey exploring automation, cloud deployment, and AI integration. I’ve been hands-on, building real workflows and connecting actual services. Here’s what I discovered along the way.
Getting Started with Automation
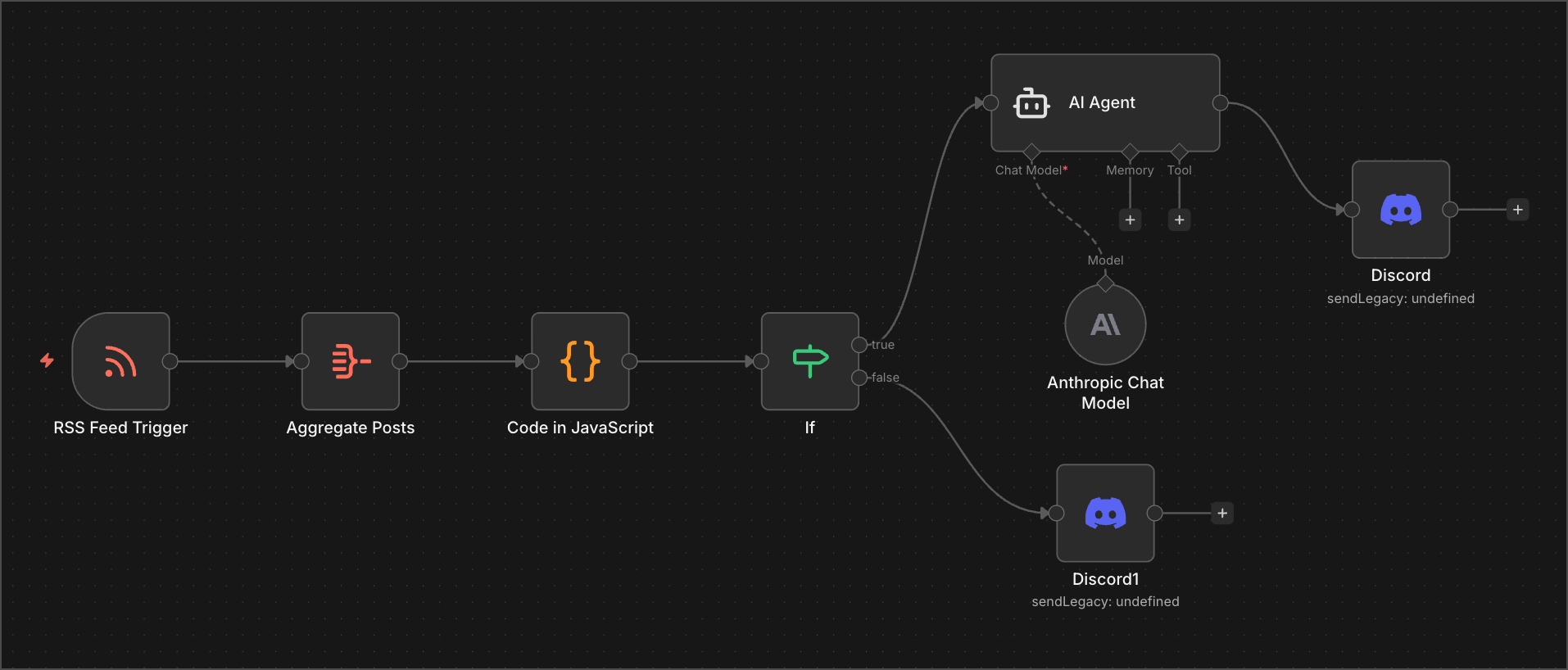
The foundation of this exploration was deploying n8n as a self-hosted instance on a cloud provider. This wasn’t just about clicking a button—it required understanding infrastructure, configuration, and the basics of running a service in the cloud. Once that was in place, I could start building workflows.
Building basic workflows in n8n taught me what it actually means to create a functional automation. It’s not enough to have a good idea; you need to understand how data flows through your workflow, how triggers initiate actions, how conditions branch logic, and how errors are handled. Meeting all the requirements for a working workflow meant learning to think systematically about each step and its dependencies.
Accelerating Learning with AI
One of the biggest breakthroughs was leveraging Claude AI to accelerate my learning across different subject matters. Rather than struggling through documentation alone or spending hours debugging, I could ask targeted questions and get explanations tailored to my specific use cases. This fundamentally changed how quickly I could iterate and experiment.
Claude became my learning partner—helping me understand concepts, troubleshoot issues, and even write code. This wasn’t just about saving time; it was about compressing what might have taken weeks of traditional learning into days of focused experimentation.
Building and Connecting
From there, I expanded into multiple directions simultaneously. I deployed Next.js apps on Vercel using Claude Code, which gave me a way to build custom web interfaces quickly. I integrated GitHub for continuous delivery, automating the process of pushing code changes to live services like Scribbles and Micro.blog.
But the real power came from connecting external services directly into n8n workflows. I learned to interact with Telegram, Discord, Micro.blog, and Tinylytics through their APIs, webhooks, and HTTP requests. Each integration taught me something different about how modern services communicate with each other. Some services have well-documented APIs; others require reverse-engineering their webhook payloads. Some are straightforward; others have quirks you only discover through experimentation.
The Deeper Challenges
The more complex problems emerged when I tackled data persistence and LLM integration within n8n. Adding state management to automation workflows isn’t trivial—you need to decide where to store data, how to retrieve it, and how to keep it synchronized across multiple workflow runs. It’s one thing to run a workflow once; it’s another to run it reliably over time while maintaining context and history.
Incorporating AI services—whether through pay-per-use models like Claude or subscription-based services—required careful consideration. I had to think about cost implications, rate limits, and how to structure requests efficiently. Suddenly, every API call had a price tag, and I became much more conscious of resource consumption.
Key Insights
What stands out most is a clearer understanding of tool selection. Each platform has its place, and knowing when to use n8n versus a custom Next.js app versus a direct API call makes all the difference. Sometimes the right answer is a simple webhook; sometimes you need the flexibility of a full application. This contextual thinking has become invaluable.
I’ve also learned to transpose ideas into concrete use cases, leveraging service APIs from Scribbles, Tinylytics, and Micro.blog in ways I hadn’t considered before. What started as “I wonder if I can connect these services” became “Here’s a specific workflow that solves a real problem.”
I’ve discovered how to make the most of services I was already depending on—Micro.blog and Inoreader—by understanding their capabilities more deeply. These tools had features and integrations I’d overlooked, and now I’m using them in ways that actually enhance my workflow.
I’ve also expanded my toolkit with utilities like VS Code, GitHub, and Postman, each playing a crucial role in different parts of the workflow. VS Code became my development environment, GitHub my version control and deployment trigger, and Postman my tool for testing and understanding APIs before integrating them into n8n.
The Bigger Picture
The journey has been about understanding not just individual tools, but how they fit together in a larger ecosystem. It’s about recognizing that modern development isn’t about mastering one tool—it’s about understanding how to orchestrate multiple tools to solve real problems. And it’s about using AI not as a replacement for learning, but as an accelerant that lets you learn faster and go deeper.